
21 GenAI UX Patterns 21種GenAI UX設計模式
生成式人工智慧(GenAI)為人機互動帶來新方式,核心是"基於意圖達成結果"。由於其機率性輸出涉及記憶、錯誤、幻覺和惡意使用等問題,設計可用、安全、可信的AI產品至關重要。
IBM指出,構建AI產品不僅是大語言模型(LLM)問題,而是多層次系統:包括記憶、編排、工具擴充套件、使用者體驗設計和代理式流程等要素。
1. 是否使用GenAI(GenAI or no GenAI)
在決定是否使用AI時,要考慮它能否真正改善使用者體驗,以及可能帶來的複雜問題。
適合使用GenAI的場景:
- 創意類任務:如寫作、筆記總結、起草回覆等。
- 複雜內容建立:如將草圖轉換成網站程式碼。
- 當使用者難以透過普通介面表達需求時。
不建議使用GenAI的場景:
- 需要準確無誤的結果:如報稅、法律檔案。
- 使用者需要固定一致的資訊:如軟體使用說明。
如何使用:
- 找出使用者使用產品時的困難點。
- 評估技術是否可行,以及投入是否值得。
- 確認使用者期望與AI系統是否匹配,參考後面的"增強vs自動化"和"心理模型"部分。

2. 把使用者需求轉為資料需求(Convert User Needs to Data Needs)
AI專案應從使用者真實需求出發,然後確定AI需要什麼資料。使用者關心的是目標和感受,而不是資料結構。
如何使用:
- 組建包含產品、設計和資料專家的團隊,共同定義使用者問題。
- 用多種方法瞭解使用者需求:
- 調查和訪談
- 行為觀察
- 使用者評論和社交媒體反饋
- 使用工具如任務分析、使用者畫像和價值主張分析。
- 確定AI模型需要哪些資料,分析現有資料是否足夠。

3. 增強(Augment)與自動化(Automate)
決定AI是幫助使用者做得更好,還是完全代替使用者完成任務。
- 適合自動化的情況:重複、費時或價值低的任務。例如:Intercom FinAI自動總結郵件。
- 適合增強的情況:使用者想保持控制權,提高效率或創意。例如:Magenta Studio輔助音樂創作。
如何使用:
- 用使用者分析工具瞭解使用者期望。
- 檢驗AI是否真的提升了體驗或反而破壞了信任。
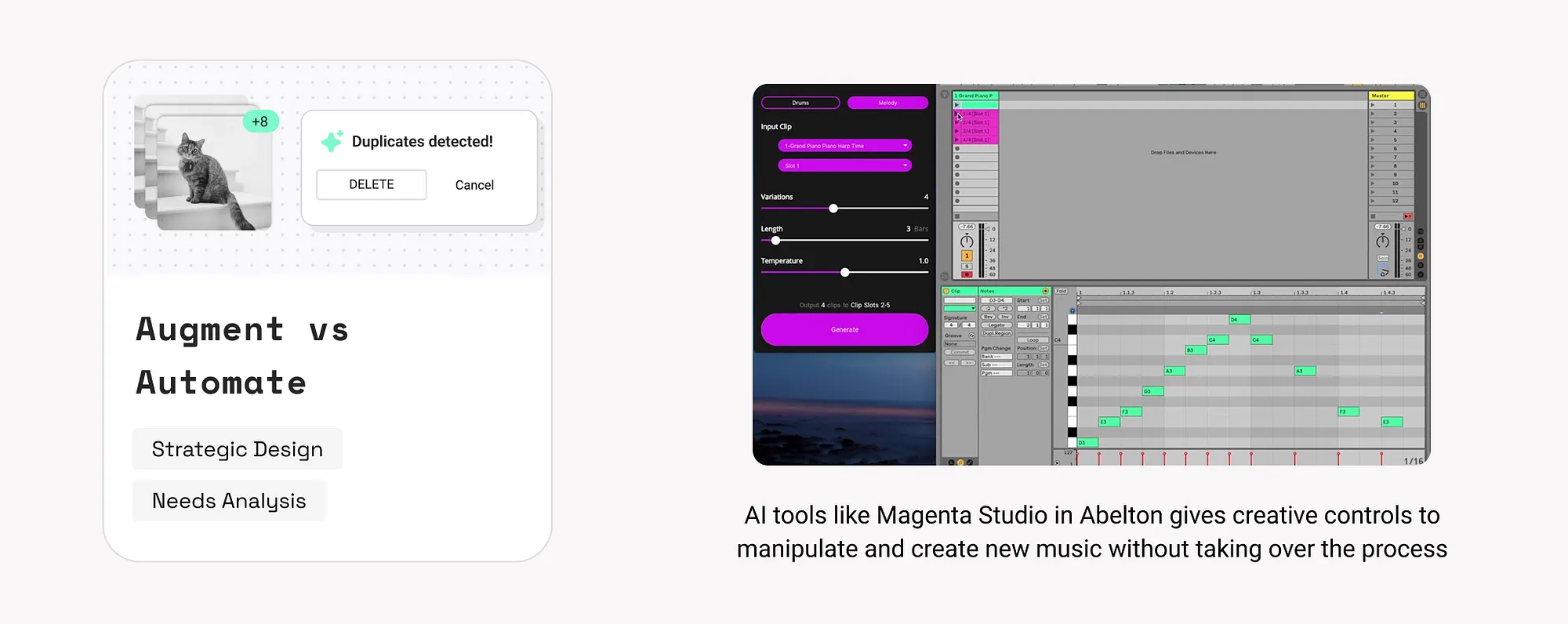
4. 自動化程度定義(Define Level of Automation)
根據使用者需求和問題,決定讓AI控制到什麼程度。
三種自動化等級:
- 無自動化:AI只提建議,使用者做決定。例如:Grammarly語法檢查。
- 部分自動化(輔助模式):AI提供初步方案,使用者可以修改。例如:GitHub Copilot程式碼助手。
- 完全自動化(代理模式):AI自己完成任務。例如:Ema自動完成競爭分析和傳送郵件。
如何使用:
- 評估任務風險:低風險任務(如提醒、篩選)適合自動化;高風險任務(如金融交易)需要人工監督。
- 在介面中明確自動化控制選項,參考第15條。
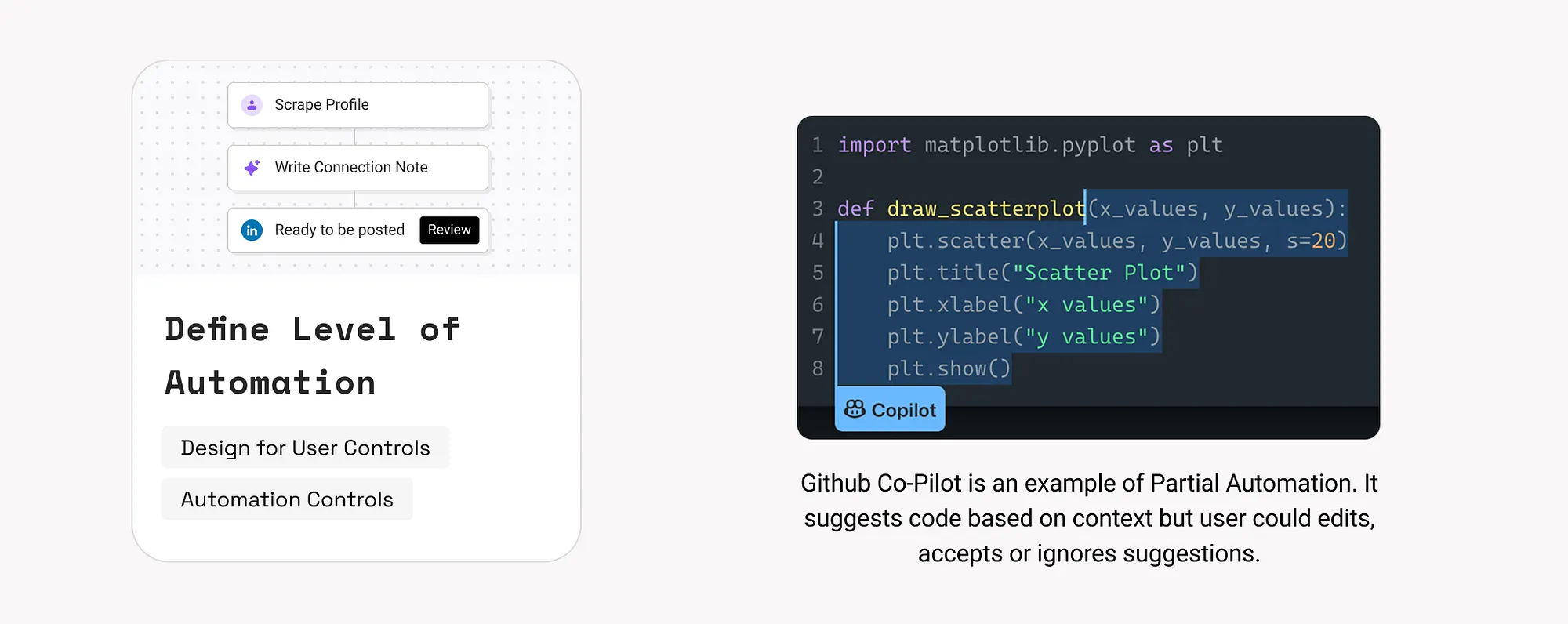
5. 漸進式GenAI使用(Progressive GenAI Adoption)
逐步引導使用者使用AI功能,幫助他們理解系統能做什麼,避免恐懼和誤解。
如何使用:
- 強調AI帶來的好處,而不是技術細節。
- 先提供基礎功能,再引導使用者使用高階功能。例如:Adobe FireFly。
- 逐步提高自動化程度(結合第4條)。
- 提供錯誤處理和恢復方法(參考第16和17條)。
- 明確說明資料使用和隱私保護(參考第21條)。
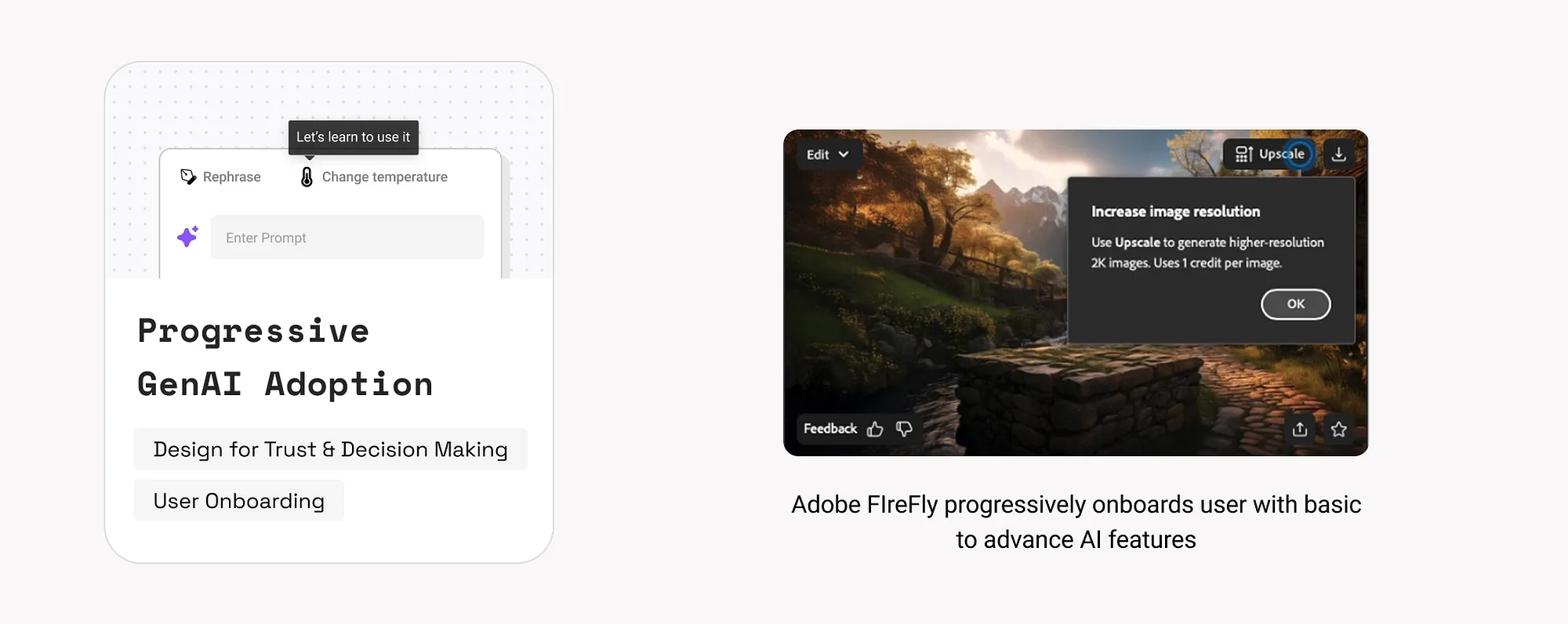
6. 利用使用者心理模型(Leverage Mental Models)
當產品設計符合使用者已有的思維習慣時,使用者更容易接受和使用。
示例:
如何使用:
- 分析使用者行為和目標,找出他們已有的思維模式。
- 如果設計打破了使用者習慣,要透過清晰的引導、說明和視覺提示幫助使用者理解。
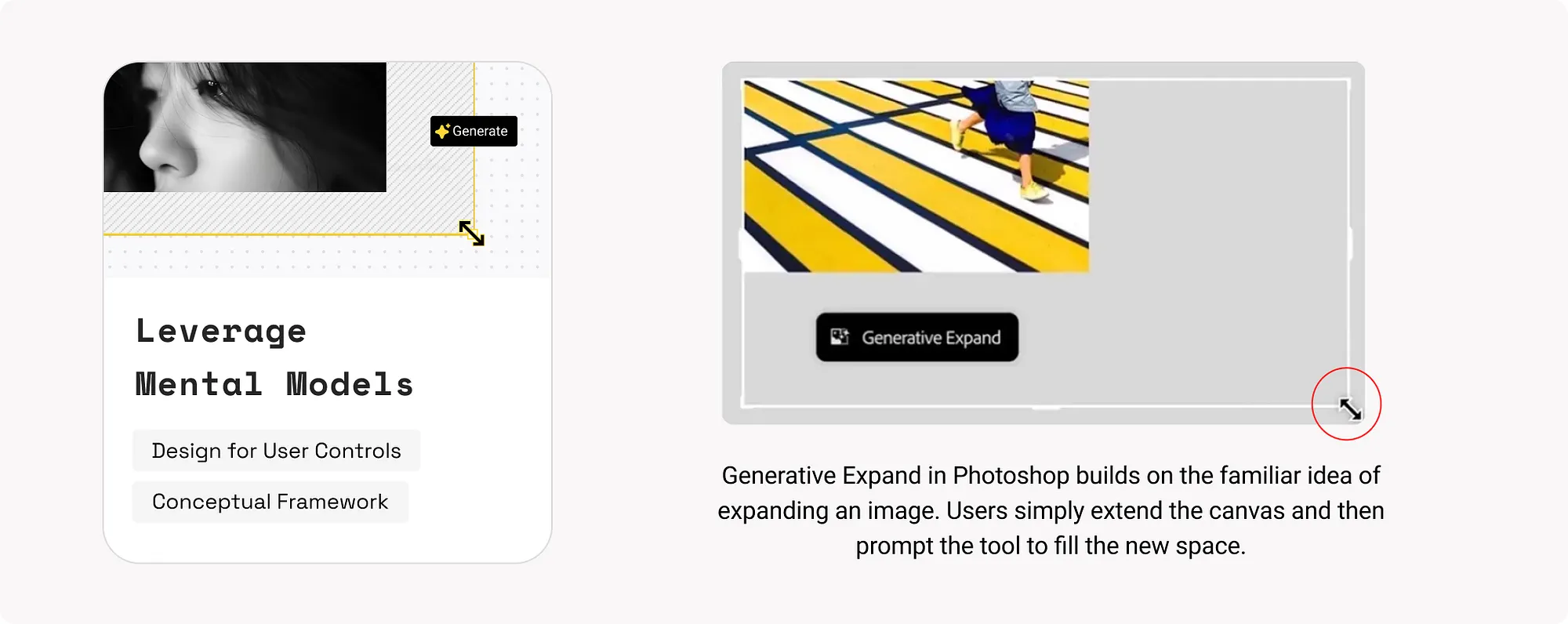
7. 表達產品限制(Convey Product Limits)
清晰地說明AI模型的能力邊界、知識覆蓋範圍以及潛在的限制,有助於建立信任並防止誤用。
示例:
- Claude會在知識超出其訓練範圍時,提示“知識截止日期”。
- Amazon Rufus當面對非購物相關問題時,會直接說明無法處理該類問題。
如何使用:
- 在產品中清楚表達模型限制:使用上下文提示、響應說明、工具提示等形式。
- 提供替代方案:當模型無法響應時,提供人工客服或其他渠道。
- 在營銷文案、使用者引導中明確能力邊界,防止使用者產生錯誤預期。
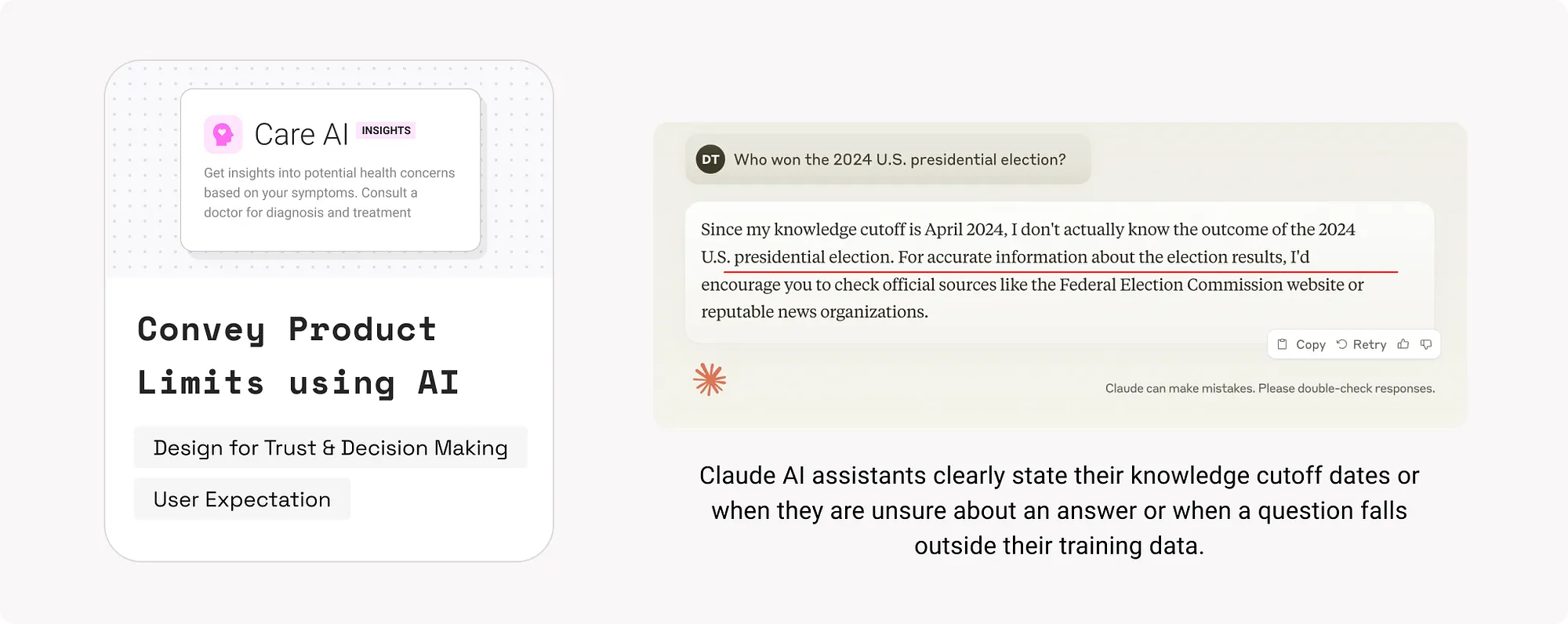
8. 展示思維鏈(Display Chain of Thought, CoT)
透過模擬人類逐步思考過程,讓使用者理解AI是如何得出答案的,增強透明度與信任。
示例:
- Perplexity會展示其推理步驟。
- Khanmigo教學AI以逐步指導方式幫助學生理解問題。
如何使用:
- 展示處理狀態(如“正在檢索”“分析中”),降低使用者焦慮。
- 採用“逐步展開”設計:先顯示摘要,使用者可點選檢視詳細推理過程。
- 明確顯示AI使用的工具或資料來源。
- 表示模型信心或不確定性,提示使用者是否應進一步核實資訊。
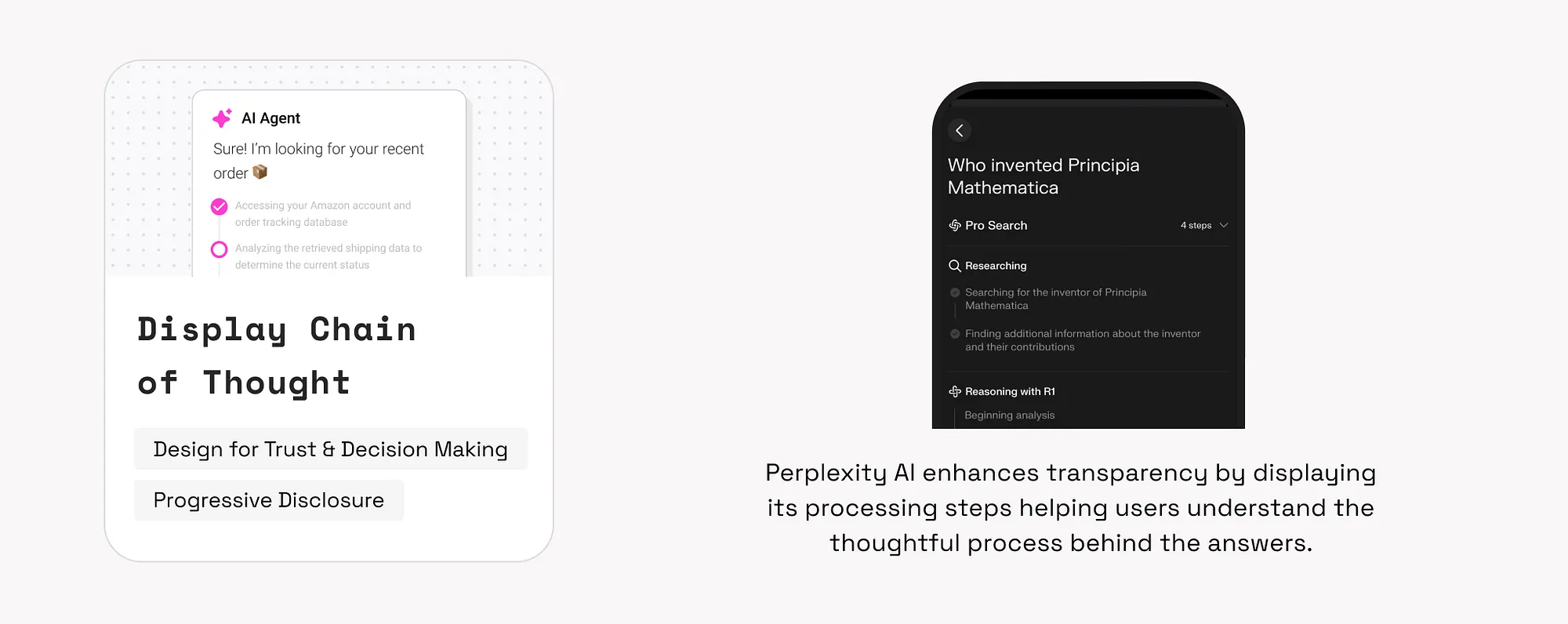
9. 利用多樣輸出(Leverage Multiple Outputs)
利用GenAI的機率性特性,提供多個輸出供使用者選擇,有助於激發創意或最佳化決策。
示例:
- Google Gemini提供多個回答選項供使用者比較選擇。
如何使用:
- 說明多樣輸出的目的:幫助使用者探索不同方向或理解問題的多種可能。
- 支援使用者編輯、評分或混合多個輸出。如Midjourney 提供“Remix”選項引導使用者細化生成內容。
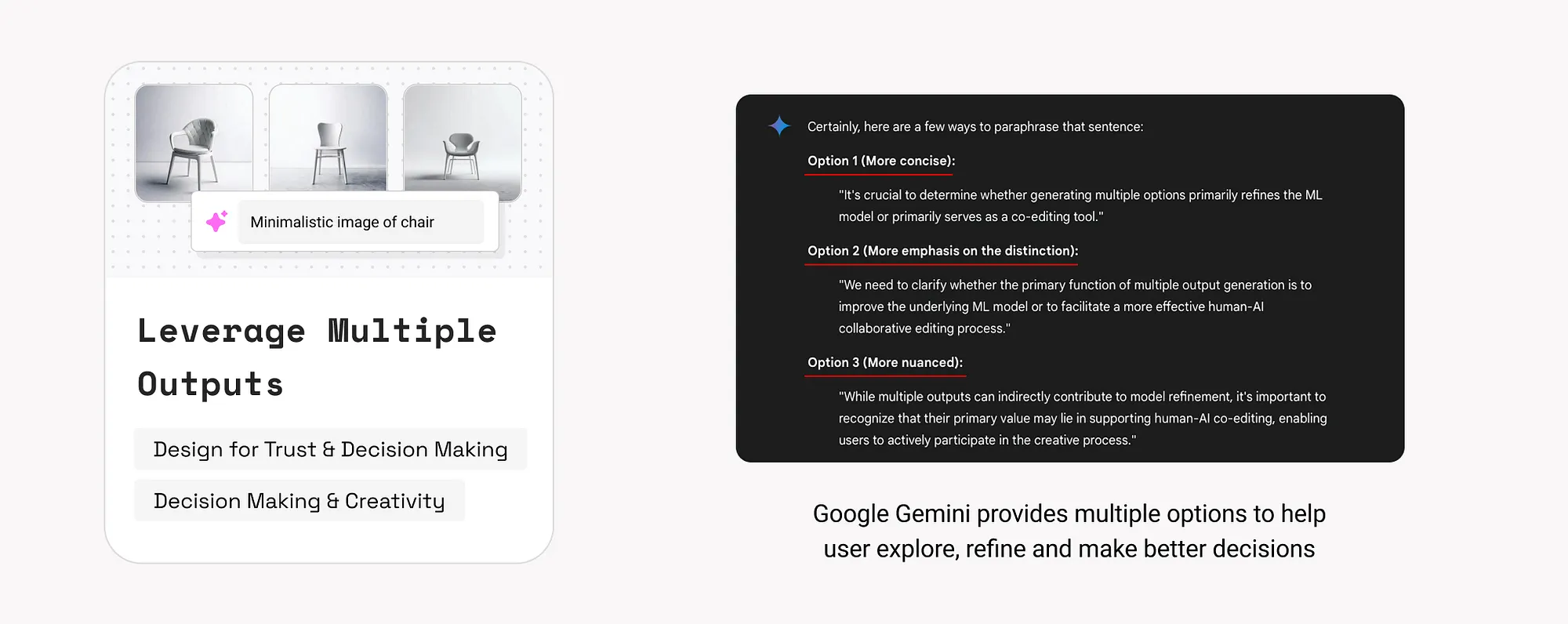
10. 提供資料來源(Provide Data Sources)
展示AI輸出背後的資料依據,有助於提升資訊可信度,尤其在高風險領域(如醫療、金融、法律)尤為關鍵。
示例:
- Google NotebookLM為答案新增引用,連結至原始檔案內容。
- Adobe Firefly公佈其訓練資料來源為授權圖片或公共版權素材。
如何使用:
- 在回答中加入引用或可展開的資料來源連結。
- 解釋模型訓練資料的覆蓋範圍與排除項。
- 針對多個資料來源的情況,區分不同可信等級的資料並作出視覺區分。
11. 表達模型信心(Convey Model Confidence)
透過顯示AI模型對輸出的置信度,幫助使用者判斷資訊的可靠性,做出更合適的決策。
示例:
如何使用:
- 判斷場景是否需要信心提示:
- 高風險場景必須提示信心程度。
- 低風險場景(如生成藝術、故事)可避免幹擾體驗。
- 選擇合適的表達形式:
- 百分比、進度條或語言提示。
- 在低信心情況下提供後續建議,如“是否需要進一步確認?”或“檢視其他選項”。

12. 設計記憶與回憶功能(Design for Memory and Recall)
允許AI記住使用者的歷史資訊、偏好或任務進度,有助於提高個性化體驗,降低重複操作。
示例:
如何使用:
- 定義記憶場景與型別:
- 短期記憶:僅在當前會話中有效。
- 長期記憶:跨會話使用,如專案規劃、使用者偏好等。
- 在對話中自然呼叫記憶內容,例如:“你上次說希望語氣更輕鬆,要繼續這樣嗎?”
- 提供清晰的資料控制入口:使用者可以檢視、編輯或刪除記憶。ChatGPT 提供完整的記憶管理介面。

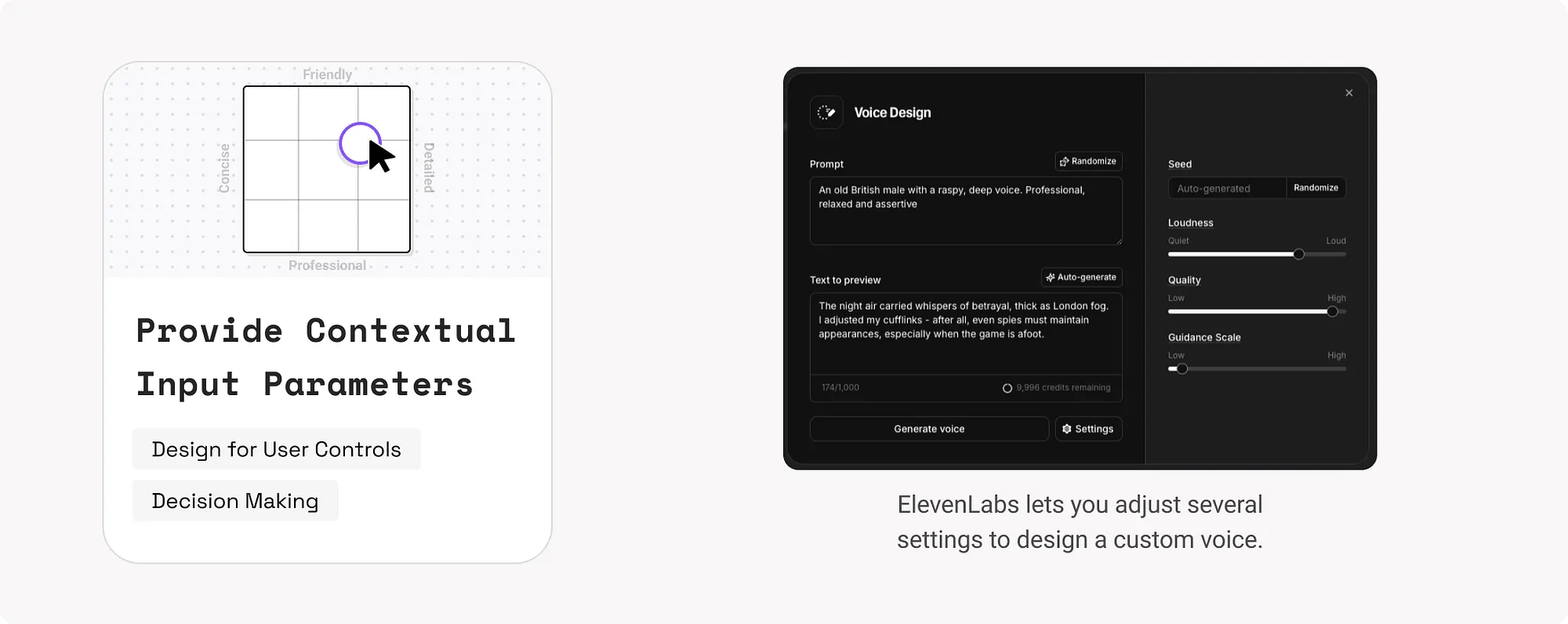
13. 提供上下文輸入引數(Provide Contextual Input Parameters)
透過自動填寫或建議使用者個性化設定,使互動更快捷精準,減少使用者認知負擔。
示例:
- ElevenLabs提供多個引數讓使用者自定義語音。
- Perplexity根據使用者當前查詢,智慧推薦後續問題。
如何使用:
- 自動填充歷史輸入或偏好設定(參考記憶模式)。
- 實時提示智慧補全建議。
- 根據使用者行為或場景,動態提供互動控制元件(如滑動條、核取方塊等)。
14. 協作式/共同編輯設計(Design for Co-Pilot / Co-Editing / Partial Automation)
AI作為助手存在,使用者保持決策權。這在創意、寫作、設計、程式設計等主觀性強的任務中尤為重要。
示例:
如何使用:
- 將AI建議嵌入上下文中,使用者可隨時修改。
- 允許使用者設定創作意圖,如目標、語調、示例。
- 保留使用者最終控制權,使AI成為靈感加速器而非取代者。
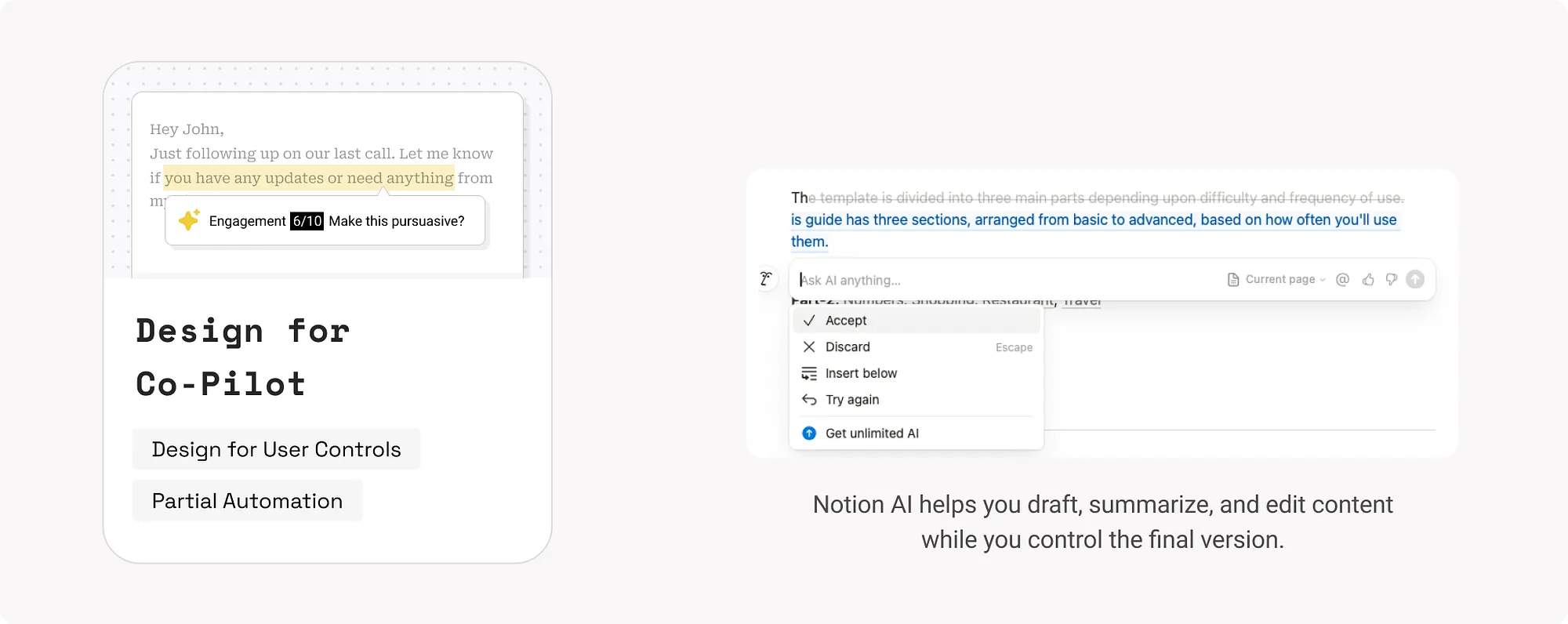
15. 自動化使用者控制設計(Design User Controls for Automation)
讓使用者透過介面控制AI的自動化程度,確保使用者在AI行為不符合預期時能及時幹預,避免失控。
示例:
如何使用:
- 漸進式展示控制:從簡單功能開始,引導使用者逐步解鎖更復雜的自動化能力。
- 提供明確的UI控制元件:如開關按鈕、滑塊、選擇項,讓使用者自行選擇AI自動化的時機與範圍。
- 錯誤恢復機制:當AI結果不準確時,提供“撤銷”“手動編輯”“人工協助”等備選路徑。

16. 使用者輸入錯誤處理設計(Design for User Input Error States)
使用者輸入可能含糊不清或不完整,AI需要有策略應對,以維持互動流暢性。
示例:
- ChatGPT 面對不明確問題(如“首都是哪?”)時,會主動提出澄清問題,而不是武斷回答。
如何使用:
- 自動糾錯:當模型識別拼寫錯誤且信心較高時,使用拼寫檢查或模糊匹配自動糾正常見輸入錯誤,並巧妙地顯示更正
- 提問澄清:當使用者輸入模糊、上下文不足時,引導使用者補充資訊,瞭解更多關於實體和意圖的資訊。而非直接推測答案。
- 提供快速修正方式:例如顯示“編輯”按鈕,便於使用者快速修改原始輸入。

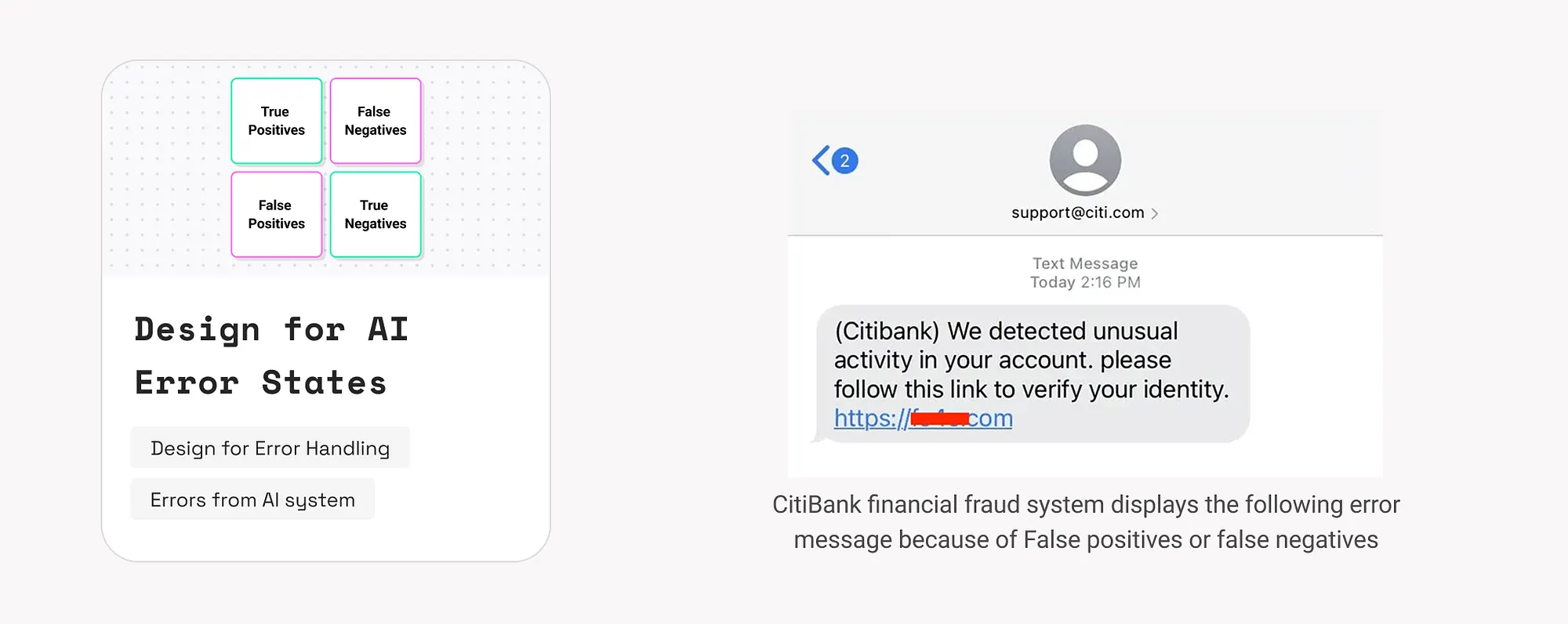
17. AI系統錯誤處理設計(Design for AI System Error States)
AI系統出錯是不可避免的,需設計適當機制幫助使用者識別問題並恢復操作。
常見錯誤型別:
- 系統失敗(如虛假輸出):可能由幻覺或偏差導致。
- 系統侷限(無響應):例如因訓練資料不足無法回答。
- 語境錯誤(使用者誤解):輸出雖然技術上正確,但使用者不理解或被誤導。
示例:
- CitiBank 的金融風控系統如出現錯誤判斷,會提示“如為本人交易,請驗證身份”。
如何使用:
- 使用模糊語句降低信任風險:“這可能不完全準確”“我們正在改進答案質量”。
- 提供恢復路徑:比如“嘗試不同的問題”“聯絡客服”等。
- 收集反饋:讓使用者標記錯誤內容,有助於模型迭代最佳化(詳見第18條)。
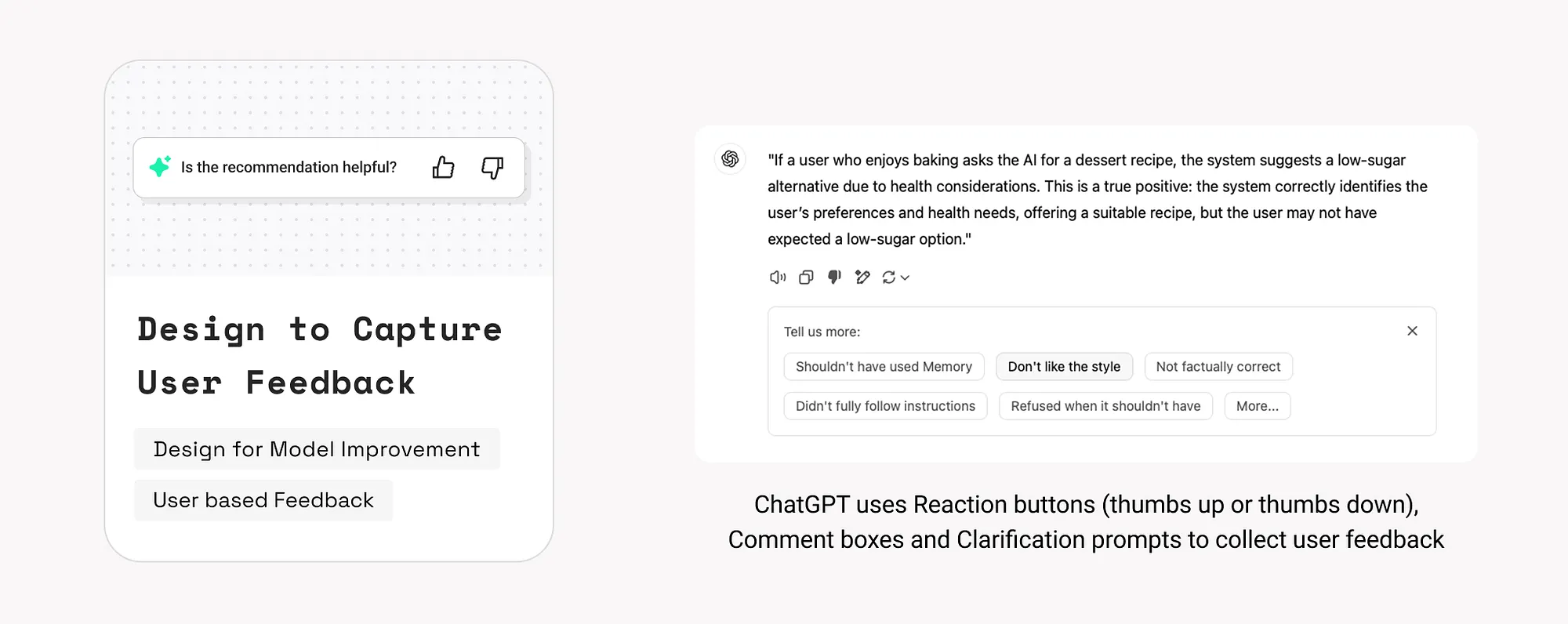
18. 設計使用者反饋機制(Design to Capture User Feedback)
使用者行為和反饋是提升模型效能與產品體驗的重要依據。需要建立反饋閉環。
示例:
- ChatGPT 允許使用者對回答點贊、點踩或發表評論,用於訓練改進。
如何使用:
- 捕捉隱性反饋:如跳過、刪除、修改建議、使用頻率等行為訊號。
- 收集顯性反饋:透過評分、問卷、評價按鈕直接獲取意見。
- 告知使用者反饋用途:例如“你的反饋有助於提升回答質量”,增強參與意願與信任。
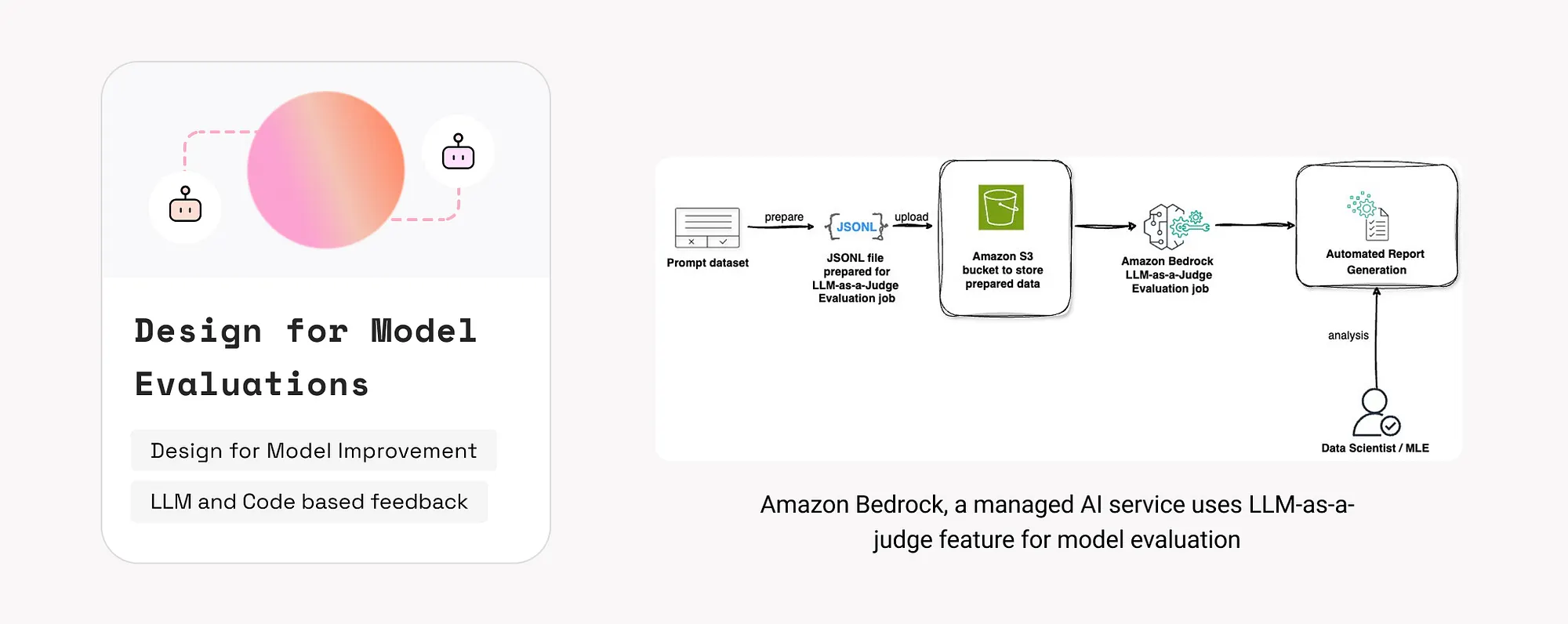
19. 模型評估機制設計(Design for Model Evaluation)
GenAI系統需在訓練階段和部署後持續評估,確保準確性、安全性和使用者契合度。
評估方法:Beyond vibe checks: A PM’s complete guide to evals
- LLM 自動評估(LLM-as-a-Judge):由獨立模型判定輸出是否合理。
- 程式碼級測試:透過已知輸入輸出資料驗證模型正確性。
- 人工評估:使用者透過介面直接標註輸出質量。
示例:
如何使用:
- 在產品中嵌入簡便的使用者評估入口,記錄哪些輸出有幫助、哪些有害。
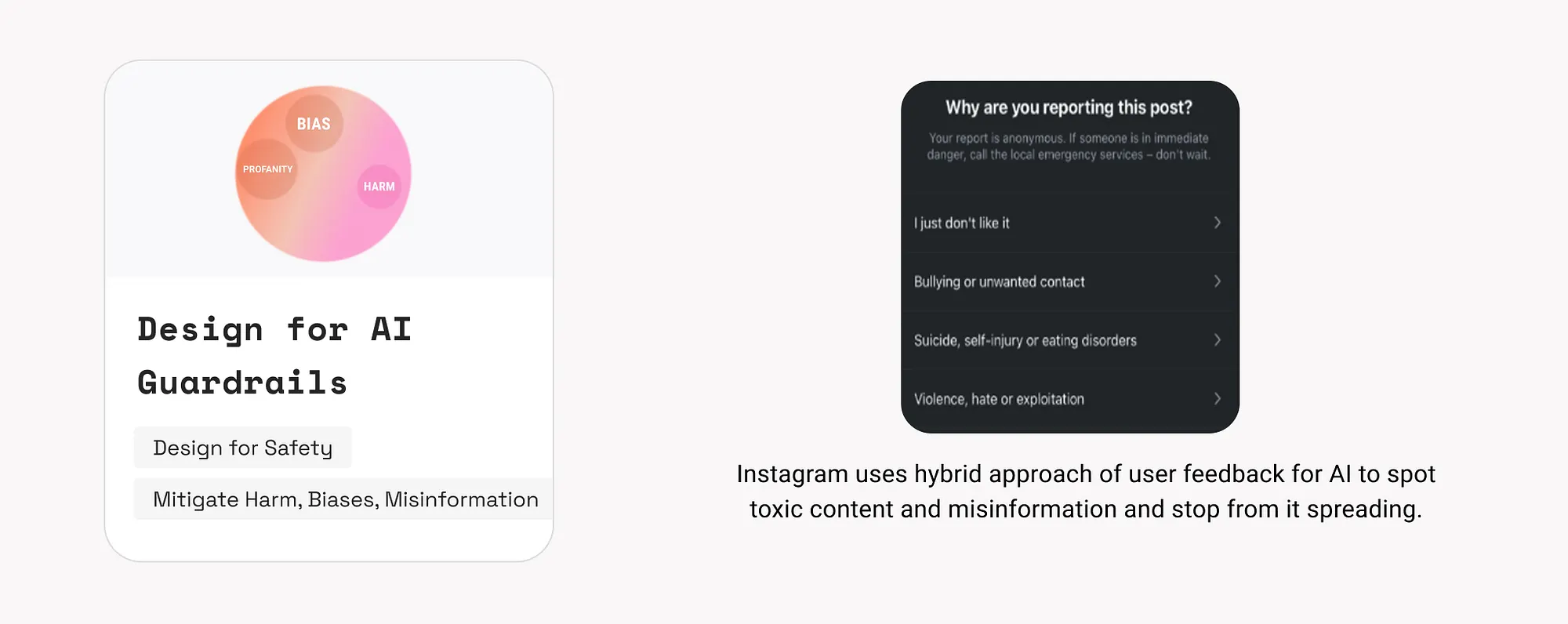
20. AI安全機制設計(Design for AI Guardrails)
設定安全防線,防止生成有害、不實、帶偏見或不適當的內容,保障使用者特別是未成年人的使用安全。
其核心目標包括:
- 保護使用者尤其是兒童群體:防止暴力、辱罵性語言、虛假內容或有偏見的資訊影響使用者。
- 例如防止模型生成種族歧視、性別歧視、政治煽動或性暗示內容。
- AI系統應主動過濾或引導使用者遠離此類內容。
- 構建信任與促進使用:當使用者知道系統具備識別並阻止仇恨言論和假資訊的能力時,會更願意長期使用該產品。
- 安全感和可控性是推動AI普及和長期留存的關鍵。
- 遵守倫理與法律合規:
- 例如《歐盟AI法案》(EU AI Act)等新興法規要求企業設計“可控、安全、可解釋”的AI系統。
- 違規可能導致嚴重法律責任和聲譽風險。
示例:
- Miko機器人遇到髒話會回應:“我不能使用這種語言”。
如何使用:
- 引導使用者輸入:對於潛在危險的提問,引導使用者改寫語句。
- 實時輸出審查與修改:在模型生成內容前後進行篩查或替換,並提示“此回答已根據安全政策調整”。
- 提示使用者注意風險:如“這不是醫療建議,僅供參考”。
- 鼓勵反饋:提供標記不當內容的入口,持續最佳化模型表現。
- 多重驗證高風險資訊:如結合權威資料庫驗證結果(參見第10條資料來源設計)。
21. 資料隱私與控制透明化(Communicate Data Privacy and Controls)
AI系統常依賴敏感或行為資料,需明確告知使用者資料如何被收集、使用、儲存與保護。
示例:
如何使用:
- 提供明確的資料說明:使用者使用某項AI功能時,說明訪問哪些資料以及用途。
- 支援資料許可權選擇:使用者可自由開啟或關閉資料採集、使用偏好。
- 提供資料管理功能:允許使用者檢視、下載或刪除其歷史資料。
